diff options
| author | Dimitri Staessens <[email protected]> | 2019-07-05 22:27:04 +0200 |
|---|---|---|
| committer | Dimitri Staessens <[email protected]> | 2019-07-05 22:27:04 +0200 |
| commit | 95258be27446b3584528c5bc7177aca40ddba2d5 (patch) | |
| tree | f918e4415eacaacf6e4c7b0d00337990f9095bc4 /content/docs | |
| parent | e5d3f80261ebaed768ad718bd6fce0df848586fb (diff) | |
| download | website-95258be27446b3584528c5bc7177aca40ddba2d5.tar.gz website-95258be27446b3584528c5bc7177aca40ddba2d5.zip | |
content: Reorganize to better suit ananke theme
Diffstat (limited to 'content/docs')
| -rw-r--r-- | content/docs/_index.md | 6 | ||||
| -rw-r--r-- | content/docs/compopt.html | 435 | ||||
| -rw-r--r-- | content/docs/development/_index.md | 6 | ||||
| -rw-r--r-- | content/docs/documentation.md | 41 | ||||
| -rw-r--r-- | content/docs/faq.md | 122 | ||||
| -rw-r--r-- | content/docs/manuals.md | 18 | ||||
| -rw-r--r-- | content/docs/performance.md | 74 | ||||
| -rw-r--r-- | content/docs/quickstart.md | 11 | ||||
| -rw-r--r-- | content/docs/tutorials/_index.md | 5 | ||||
| -rw-r--r-- | content/docs/tutorials/dev-tut-1.md | 73 | ||||
| -rw-r--r-- | content/docs/tutorials/tutorial-1.md | 153 | ||||
| -rw-r--r-- | content/docs/tutorials/tutorial-2.md | 297 | ||||
| -rw-r--r-- | content/docs/tutorials/tutorial-3.md | 210 | ||||
| -rw-r--r-- | content/docs/tutorials/tutorial-4.md | 123 |
14 files changed, 1574 insertions, 0 deletions
diff --git a/content/docs/_index.md b/content/docs/_index.md new file mode 100644 index 0000000..f2a842a --- /dev/null +++ b/content/docs/_index.md @@ -0,0 +1,6 @@ +--- +title: Documentation +date: 2019-06-22 +type: page +draft: false +--- diff --git a/content/docs/compopt.html b/content/docs/compopt.html new file mode 100644 index 0000000..4c4459c --- /dev/null +++ b/content/docs/compopt.html @@ -0,0 +1,435 @@ +--- +title: "Compilation options" +date: 2019-06-22 +draft: false +--- + +<p> + Below is a list of the compile-time configuration options for + Ouroboros. These can be set using +</p> +<pre><code>$ cmake -D<option>=<value> ..</code></pre> +<p>or using</p> +<pre><code>ccmake .</code></pre> +<p> + Options will only show up in ccmake if they are relevant for + your system configuration. The default value for each option + is <u>underlined</u>. Boolean values will print as ON/OFF in + ccmake instead of True/False. +</p> +<table> + <tr> + <th>Option</th> + <th>Description</th> + <th>Values</th> + </tr> + <tr> + <th colspan="3">Compilation options</th> + </tr> + <tr> + <td>CMAKE_BUILD_TYPE</td> + <td> + Set the build type for Ouroboros. Debug builds will add some + extra logging. The debug build can further enable the + address sanitizer (ASan) thread sanitizer (TSan) and leak + sanitizer (LSan) options. + </td> + <td> + <u>Release</u>, Debug, DebugASan, DebugTSan, DebugLSan + </td> + </tr> + <tr> + <td>CMAKE_INSTALL_PREFIX</td> + <td> + Set a path prefix in order to install Ouroboros in a + sandboxed environment. Default is a system-wide install. + </td> + <td> + <path> + </td> + </tr> + <tr> + <td>DISABLE_SWIG</td> + <td> + Disable SWIG support. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <th colspan="3">Library options</th> + <tr> + <tr> + <td>DISABLE_FUSE</td> + <td> + Disable FUSE support, removing the virtual filesystem under + <FUSE_PREFIX>. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>FUSE_PREFIX</td> + <td> + Set the path where the fuse system should be + mounted. Default is /tmp/ouroboros. + </td> + <td> + <path> + </td> + </tr> + <tr> + <td>DISABLE_LIBGCRYPT</td> + <td> + Disable support for using the libgcrypt library for + cryptographically secure random number generation and + hashing. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>DISABLE_OPENSSL</td> + <td> + Disable support for the libssl library for cryptographic + random number generation and hashing. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>DISABLE_ROBUST_MUTEXES</td> + <td> + Disable + <a href="http://pubs.opengroup.org/onlinepubs/9699919799/functions/pthread_mutexattr_getrobust.html"> + robust mutex + </a> + support. Without robust mutex support, Ouroboros may lock up + if processes are killed using SIGKILL. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>PTHREAD_COND_CLOCK</td> + <td> + Set the + <a href="http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/time.h.html"> + clock type + </a> + to use for timeouts for pthread condition variables. Default + on Linux/FreeBSD: CLOCK_MONOTONIC. Default on OS X: + CLOCK_REALTIME. + </td> + <td> + <clock_id_t> + </td> + </tr> + <tr> + <th colspan="3">Shared memory system options</th> + <tr> + <tr> + <td>SHM_PREFIX</td> + <td> + Set a prefix for the shared memory filenames. The mandatory + leading + <a href="http://pubs.opengroup.org/onlinepubs/9699919799/functions/shm_open.html"> + slash + </a> + is added by the build system. Default is "ouroboros". + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>SHM_BUFFER_SIZE</td> + <td> + Set the maximum total number of packet blocks Ouroboros + can buffer at any point in time. Must be a power of 2. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>SHM_RDRB_BLOCK_SIZE</td> + <td> + Set the size of a packet block. Default: page size of the + system. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>SHM_RDRB_MULTI-BLOCK</td> + <td> + Allow packets that are larger than a single packet block. + </td> + <td> + <u>True</u>, False + </td> + </tr> + <tr> + <td>DU_BUFF_HEADSPACE</td> + <td> + Set the amount of space to allow for the addition of + protocol headers when a new packet buffer is passed to the + system. Default: 128 bytes. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>DU_BUFF_TAILSPACE</td> + <td> + Set the amount of space to allow for the addition of + protocol tail information (CRCs) when a new packet buffer + is passed to the system. Default: 32 bytes. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <th colspan="3">IRMd options</th> + </tr> + <tr> + <td>SYS_MAX_FLOWS</td> + <td> + The maximum number of flows this Ouroboros system can + allocate. Default: 10240. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>SOCKET_TIMEOUT</td> + <td> + The IRMd sends commands to IPCPs over UNIX sockets. This + sets the timeout for such commands in milliseconds. Some + commands can be set independently. Default: 1000. + </td> + <td> + <time_t> + </td> + </tr> + <tr> + <td>BOOTSTRAP_TIMEOUT</td> + <td> + Timeout for the IRMd to wait for a response to a bootstrap + command from an IPCP in milliseconds. Default: 5000. + </td> + <td> + <time_t> + </td> + </tr> + <tr> + <td>ENROLL_TIMEOUT</td> + <td> + Timeout for the IRMd to wait for a response to an enroll + command from an IPCP in milliseconds. Default: 60000. + </td> + <td> + <time_t> + </td> + </tr> + <tr> + <td>CONNECT_TIMEOUT</td> + <td> + Timeout for the IRMd to wait for a response to a connect + command from an IPCP in milliseconds. Default: 5000. + </td> + <td> + <time_t> + </td> + </tr> + <tr> + <td>REG_TIMEOUT</td> + <td> + Timeout for the IRMd to wait for a response to a register + command from an IPCP in milliseconds. Default: 3000. + </td> + <td> + <time_t> + </td> + </tr> + <tr> + <td>QUERY_TIMEOUT</td> + <td> + Timeout for the IRMd to wait for a response to a query + command from an IPCP in milliseconds. Default: 3000. + </td> + <td> + <time_t> + </td> + </tr> + <tr> + <td>IRMD_MIN_THREADS</td> + <td> + The minimum number of threads in the threadpool the IRMd + keeps waiting for commands. Default: 8. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>IRMD_ADD_THREADS</td> + <td> + The number of threads the IRMd will create if the current + available threadpool is lower than + IRMD_MIN_THREADS. Default: 8. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <th colspan="3">IPCP options</th> + </tr> + <tr> + <td>DISABLE_RAPTOR</td> + <td> + Disable support for the raptor NetFPGA implementation. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>DISABLE_BPF</td> + <td> + Disable support for the Berkeley Packet Filter device + interface for the Ethernet LLC layer. If no suitable + interface is found, the LLC layer will not be built. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>DISABLE_NETMAP</td> + <td> + Disable <a href="http://info.iet.unipi.it/~luigi/netmap/">netmap</a> + support for the Ethernet LLC layer. If no suitable interface + is found, the LLC layer will not be built. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>DISABLE_RAW_SOCKETS</td> + <td> + Disable raw sockets support for the Ethernet LLC layer. If + no suitable interface is found,the LLC layer will not be + built. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>DISABLE_DDNS</td> + <td> + Disable Dynamic Domain Name System support for the UDP + layer. + </td> + <td> + True, <u>False</u> + </td> + </tr> + <tr> + <td>IPCP_SCHED_THR_MUL</td> + <td> + The number of scheduler threads an IPCP runs per QoS + cube. Default is 2. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>IPCP_QOS_CUBE_BE_PRIORITY</td> + <td> + Priority for the best effort qos cube scheduler + thread. This is mapped to a system value. Scheduler + threads have at least half the system max priority value. + </td> + <td> + <u>0</u>..99 + </td> + </tr> + <tr> + <td>IPCP_QOS_CUBE_VIDEO_PRIORITY</td> + <td> + Priority for the video qos cube scheduler thread. This is + mapped to a system value. Scheduler threads have at least + half the system max priority value. + </td> + <td> + 0..<u>90</u>..99 + </td> + </tr> + <tr> + <td>IPCP_QOS_CUBE_VOICE_PRIORITY</td> + <td> + Priority for the voice qos cube scheduler thread. This is + mapped to a system value. Scheduler threads have at least + half the system max priority value. + </td> + <td> + 0..<u>99</u> + </td> + </tr> + <tr> + <td>IPCP_FLOW_STATS</td> + <td> + Enable statistics for the data transfer component. + </td> + <td> + True, <u>False</u> + </td> + </tr> + + <tr> + <td>PFT_SIZE</td> + <td> + The forwarding table in the normal IPCP uses a + hashtable. This sets the size of this hash table. Default: 4096. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>IPCP_MIN_THREADS</td> + <td> + The minimum number of threads in the threadpool the IPCP + keeps waiting for commands. Default: 4. + </td> + <td> + <size_t> + </td> + </tr> + <tr> + <td>IPCP_ADD_THREADS</td> + <td> + The number of threads the IPCP will create if the current + available threadpool is lower than + IPCP_MIN_THREADS. Default:4. + </td> + <td> + <size_t> + </td> + </tr> +</table> diff --git a/content/docs/development/_index.md b/content/docs/development/_index.md new file mode 100644 index 0000000..0a5257f --- /dev/null +++ b/content/docs/development/_index.md @@ -0,0 +1,6 @@ +--- +title: Development +date: 2019-06-22 +#description: Ouroboros development blog +draft: false +--- diff --git a/content/docs/documentation.md b/content/docs/documentation.md new file mode 100644 index 0000000..f48e03c --- /dev/null +++ b/content/docs/documentation.md @@ -0,0 +1,41 @@ +--- +title: "Documentation" +date: 2019-06-22 +type: page +draft: false +--- + +# Getting started + +* [Requirements](/requirements/) +* [Download Ouroboros](/download/) +* [Installing Ouroboros](/install/) +* [Compilation options](/compopt/) + +# User tutorials + +These tutorials will be kept up-to-date for the latest version of +Ouroboros. Check the version that is installed on your system using: + +``` +$ irmd --version +``` + +The output shown in the tutorials uses a [*debug*](/compopt) build +of Ouroboros, with FUSE installed and IPCP\_FLOW\_STATS enabled to show +some additional details of what is happening. + +* [Tutorial 1: Local test](/tutorial-1/) +* [Tutorial 2: Adding a layer](/tutorial-2/) +* [Tutorial 3: IPCP statistics](/tutorial-3/) +* [Tutorial 4: Connecting two machines over Ethernet](/tutorial-4/) + +# Developer tutorials + +* [Developer tutorial 1: Writing your first Ouroboros C program](/dev-tut-1/) + +# Extra info + +* [Manual pages](/manuals/) +* [Frequently Asked Questions (FAQ)](/faq/) +* [Performance tests](/performance/) diff --git a/content/docs/faq.md b/content/docs/faq.md new file mode 100644 index 0000000..b3ac687 --- /dev/null +++ b/content/docs/faq.md @@ -0,0 +1,122 @@ +--- +title: "Frequently Asked Questions (FAQ)" +date: 2019-06-22 +draft: false +--- + +Got a question that is not listed here? Just pop it on our IRC channel +or mailing list and we will be happy to answer it! + +[What is Ouroboros?](#what)\ +[Is Ouroboros the same as the Recursive InterNetwork Architecture +(RINA)?](#rina)\ +[How can I use Ouroboros right now?](#deploy)\ +[What are the benefits of Ouroboros?](#benefits)\ +[How do you manage the namespaces?](#namespaces)\ + +### <a name="what">What is Ouroboros?</a> + +Ouroboros is a packet-based IPC mechanism. It allows programs to +communicate by sending messages, and provides a very simple API to do +so. At its core, it's an implementation of a recursive network +architecture. It can run next to, or over, common network technologies +such as Ethernet and IP. + +[[back to top](#top)] + +### <a name="rina">Is Ouroboros the same as the Recursive InterNetwork Architecture (RINA)?</a> + +No. Ouroboros is a recursive network, and is born as part of our +research into RINA networks. Without the pioneering work of John Day and +others on RINA, Ouroboros would not exist. We consider the RINA model an +elegant way to think about distributed applications and networks. + +However, there are major architectural differences between Ouroboros and +RINA. The most important difference is the location of the "transport +functions" which are related to connection management, such as +fragmentation, packet ordering and automated repeat request (ARQ). RINA +places these functions in special applications called IPCPs that form +layers known as Distributed IPC Facilities (DIFs) as part of a protocol +called EFCP. This allows a RINA DIF to provide an *IPC service* to the +layer on top. + +Ouroboros has those functions in *every* application. The benefit of +this approach is that it is possible to multi-home applications in +different networks, and still have a reliable connection. It is also +more resilient since every connection is - at least in theory - +recoverable unless the application itself crashes. So, Ouroboros IPCPs +form a layer that only provides *IPC resources*. The application does +its connection management, which is implemented in the Ouroboros +library. This architectural difference impact the components and +protocols that underly the network, which are all different from RINA. + +This change has a major impact on other components and protocols. We are +preparing a research paper on Ouroboros that will contain all these +details and more. + +[[back to top](#top)] + +### <a name="deploy">How can I use Ouroboros right now?</a> + +At this point, Ouroboros is a useable prototype. You can use it to build +small deployments for personal use. There is no global Ouroboros network +yet, but if you're interested in helping us set that up, contact us on +our channel or mailing list. + +[[back to top](#top)] + +### <a name="benefits">What are the benefits of Ouroboros?</a> + +We get this question a lot, and there is no single simple answer to +it. Its benefits are those of a RINA network and more. In general, if +two systems provide the same service, simpler systems tend to be the +more robust and reliable ones. This is why we designed Ouroboros the +way we did. It has a bunch of small improvements over current networks +which may not look like anything game-changing by themselves, but do +add up. The reaction we usually get when demonstrating Ouroboros, is +that it makes everything really really easy. + +Some benefits are improved anonymity as we do not send source addresses +in our data transfer packets. This also prevents all kinds of swerve and +amplification attacks. The packet structures are not fixed (as the +number of layers is not fixed), so there is no fast way to decode a +packet when captured "raw" on the wire. It also makes Deep Packet +Inspection harder to do. By attaching names to data transfer components +(so there can be multiple of these to form an "address"), we can +significantly reduce routing table sizes. + +The API is very simple and universal, so we can run applications as +close to the hardware as possible to reduce latency. Currently it +requires quite some work from the application programmer to create +programs that run directly over Ethernet or over UDP or over TCP. With +the Ouroboros API, the application doesn't need to be changed. Even if +somebody comes up with a different transmission technology, the +application will never need to be modified to run over it. + +Ouroboros also makes it easy to run different instances of the same +application on the same server and load-balance them. In IP networks +this requires at least some NAT trickery (since each application is tied +to an interface:port). For instance, it takes no effort at all to run +three different webserver implementations and load-balance flows between +them for resiliency and seamless attack mitigation. + +The architecture still needs to be evaluated at scale. Ultimately, the +only way to get the numbers, are to get a large (pre-)production +deployment with real users. + +[[back to top](#top)] + +### <a name="namespaces">How do you manage the namespaces?</a> + +Ouroboros uses names that are attached to programs and processes. The +layer API always uses hashes and the network maps hashes to addresses +for location. This function is similar to a DNS lookup. The current +implementation uses a DHT for that function in the ipcp-normal (the +ipcp-udp uses a DynDNS server, the eth-llc and eth-dix use a local +database with broadcast queries). + +But this leaves the question how we assign names. Currently this is +ad-hoc, but eventually we will need an organized way for a global +namespace so that application names are unique. If we want to avoid a +central authority like ICANN, a distributed ledger would be a viable +technology to implement this, similar to, for instance, namecoin. diff --git a/content/docs/manuals.md b/content/docs/manuals.md new file mode 100644 index 0000000..4ce3bce --- /dev/null +++ b/content/docs/manuals.md @@ -0,0 +1,18 @@ +--- +title: "Manuals" +date: 2019-06-22 +draft: false +--- + +These are the man pages for ouroboros. If ouroboros is installed on your +system, you can also access them using "man". + +For general use of Ouroboros, refer to the [Ouroboros User +Manual](/man/man8/ouroboros.8.html). + +For use of the API, refer to the [Ouroboros Programmer's +Manual](/man/man3/flow_alloc.3.html). + +The man section also contains a +[tutorial](man/man7/ouroboros-tutorial.7.html) and a +[glossary](man/man7/ouroboros-glossary.7.html). diff --git a/content/docs/performance.md b/content/docs/performance.md new file mode 100644 index 0000000..5cd2dc0 --- /dev/null +++ b/content/docs/performance.md @@ -0,0 +1,74 @@ +--- +title: "Performance tests" +date: 2019-06-22 +draft: false +--- + +Below you will find some measurements on the performance of Ouroboros. + +### Local IPC performance test + +This test uses the *oping* tool to measure round trip time. This tools +generates traffic from a single thread. The server has a single thread +that handles ping requests and sends responses. + +``` +$ oping -n oping -i 0 -s <sdu size> +``` + +The figure below shows the round-trip-time (rtt) in milliseconds (ms) +for IPC over a local layer for different packet sizes, measured on an +Intel Core i7 4500U (2 cores @ 2.4GHz). For small payloads (up to 1500 +bytes), the rtt is quite stable at around 30 µs. This will mostly depend +on CPU frequency and to a lesser extent the OS scheduler. + + + +This test uses the *ocbr* tool to measure goodput between a sender and +receiver. The sender generates traffic from a single thread. The +receiver handles traffic from a single thread. The performance will +heavily depend on your system's memory layout (cache sizes etc). This +test was run on a Dell XPS13 9333 (2013 model). + +``` +$ ocbr -n ocbr -f -s <sdu size> +``` + + + +The goodput (Mb/s) is shown below: + + + +### Ethernet + Normal test + +This connects 2 machines over a Gb LAN using the eth-dix and a normal +layer. The oping server is registered in the dix as oping.dix and in the +normal as oping.normal. The machines (dual-socket Intel Xeon E5520) are +connected over a non-blocking switch. + +Latency test: + +ICMP ping: + +``` +--- 192.168.1.2 ping statistics --- +1000 packets transmitted, 1000 received, 0% packet loss, time 65ms +rtt min/avg/max/mdev = 0.046/0.049/0.083/0.002 ms, ipg/ewma 0.065/0.049 ms +``` + +oping over eth-dix: + +``` +--- oping.dix ping statistics --- +1000 SDUs transmitted, 1000 received, 0% packet loss, time: 66.142 ms +rtt min/avg/max/mdev = 0.098/0.112/0.290/0.010 ms +``` + +oping over eth-normal: + +``` +--- oping.normal ping statistics --- +1000 SDUs transmitted, 1000 received, 0% packet loss, time: 71.532 ms +rtt min/avg/max/mdev = 0.143/0.180/0.373/0.020 ms +```
\ No newline at end of file diff --git a/content/docs/quickstart.md b/content/docs/quickstart.md new file mode 100644 index 0000000..a1bb44b --- /dev/null +++ b/content/docs/quickstart.md @@ -0,0 +1,11 @@ +--- +title: "Quick Start" +linktitle: "Quick Start" +date: 2019-06-22 +type: page +draft: false +description: "Quick Start Guide" +--- + + +This quickstart guide is under construction.
\ No newline at end of file diff --git a/content/docs/tutorials/_index.md b/content/docs/tutorials/_index.md new file mode 100644 index 0000000..b35d0b8 --- /dev/null +++ b/content/docs/tutorials/_index.md @@ -0,0 +1,5 @@ +--- +title: "Ouroboros Tutorials" +date: 2019-06-22 +draft: false +---
\ No newline at end of file diff --git a/content/docs/tutorials/dev-tut-1.md b/content/docs/tutorials/dev-tut-1.md new file mode 100644 index 0000000..ceac8b6 --- /dev/null +++ b/content/docs/tutorials/dev-tut-1.md @@ -0,0 +1,73 @@ +--- +title: "Developer tutorial 1: Writing your first Ouroboros C program" +draft: false +--- + +This tutorial will guide you to write your first ouroboros program. It +will use the basic Ouroboros IPC Application Programming Interface. It +will has a client and a server that send a small message from the client +to the server. + +We will explain how to connect two applications. The server application +uses the flow_accept() call to accept incoming connections and the +client uses the flow_alloc() call to connect to the server. The +flow_accept and flow_alloc call have the following definitions: + +``` +int flow_accept(qosspec_t * qs, const struct timespec * timeo); +int flow_alloc(const char * dst, qosspec_t * qs, const struct +timespec * timeo); +``` + +On the server side, the flow_accept() call is a blocking call that will +wait for an incoming flow from a client. On the client side, the +flow_alloc() call is a blocking call that allocates a flow to *dst*. +Both calls return an non-negative integer number describing a "flow +descriptor", which is very similar to a file descriptor. On error, they +will return a negative error code. (See the [man +page](/man/man3/flow_alloc.html) for all details). If the *timeo* +parameter supplied is NULL, the calls will block indefinitely, otherwise +flow_alloc() will return -ETIMEDOUT when the time interval provided by +*timeo* expires. We are working on implementing non-blocking versions if +the provided *timeo* is 0. + +After the flow is allocated, the flow_read() and flow_write() calls +are used to read from the flow descriptor. They operate just like the +read() and write() POSIX calls. The default behaviour is that these +calls will block. To release the resource, the flow can be deallocated +using flow_dealloc. + +``` +ssize_t flow_write(int fd, const void * buf, size_t count); +ssize_t flow_read(int fd, void * buf, size_t count); int +flow_dealloc(int fd); +``` + +So a very simple application would just need a couple of lines of code +for both the server and the client: + +``` +/* server side */ +char msg[BUF_LEN]; +int fd = flow_accept(NULL, NULL); +flow_read(fd, msg, BUF_LEN); +flow_dealloc(fd); + +/* client side */ +char * msg = "message"; +int fd = flow_alloc("server", NULL, NULL); +flow_write(fd, msg, strlen(msg)); +flow_dealloc(fd); +``` + +The full code for an example is the +[oecho](/cgit/ouroboros/tree/src/tools/oecho/oecho.c) +application in the tools directory. + +To compile your C program from the command line, you have to link +-lourobos-dev. For instance, in the Ouroboros repository, you can do + +``` +cd src/tools/oecho +gcc -louroboros-dev oecho.c -o oecho +```
\ No newline at end of file diff --git a/content/docs/tutorials/tutorial-1.md b/content/docs/tutorials/tutorial-1.md new file mode 100644 index 0000000..d1ac3c6 --- /dev/null +++ b/content/docs/tutorials/tutorial-1.md @@ -0,0 +1,153 @@ +--- +title: "Tutorial 1: local test" +draft: false +--- + +This tutorial runs through the basics of Ouroboros. Here, we will see +the general use of two core components of Ouroboros, the IPC Resource +Manager daemon (IRMd) and an IPC Process (IPCP). + + + +We will start the IRMd, create a local IPCP, start a ping server and +connect a client. This will involve **binding (1)** that server to a +name and **registering (2)** that name into the local layer. After that +the client will be able to **allocate a flow (3)** to that name for +which the server will respond. + +We recommend to open 3 terminal windows for this tutorial. In the first +window, start the IRMd (as a superuser) in stdout mode. The output shows +the process id (pid) of the IRMd, which will be different on your +machine. + +``` +$ sudo irmd --stdout +==02301== irmd(II): Ouroboros IPC Resource Manager daemon started\... +``` + +The type of IPCP we will create is a "local" IPCP. The local IPCP is a +kind of loopback interface that is native to Ouroboros. It implements +all the functions that the Ouroboros API provides, but only for a local +scope. The IPCP create function will instantiate a new local IPC +process, which in our case has pid 2324. The "ipcp create" command +merely creates the IPCP. At this point it is not a part of a layer. We +will also need to bootstrap this IPCP in a layer, we will name it +"local_layer". As a shortcut, the bootstrap command will +automatically create an IPCP if no IPCP by than name exists, so in this +case, the IPCP create command is optional. In the second terminal, enter +the commands: + +``` +$ irm ipcp create type local name local_ipcp +$ irm ipcp bootstrap type local name local_ipcp layer local_layer +``` + +The IRMd and ipcpd output in the first terminal reads: + +``` +==02301== irmd(II): Created IPCP 2324. +==02324== ipcpd-local(II): Bootstrapped local IPCP with pid 2324. +==02301== irmd(II): Bootstrapped IPCP 2324 in layer local_layer. +``` + +From the third terminal window, let's start our oping application in +server mode ("oping --help" shows oping command line parameters): + +``` +$ oping --listen +Ouroboros ping server started. +``` + +The IRMd will notice that an oping server with pid 10539 has started: + +``` +==02301== irmd(DB): New instance (10539) of oping added. +==02301== irmd(DB): This process accepts flows for: +``` + +The server application is not yet reachable by clients. Next we will +bind the server to a name and register that name in the +"local_layer". The name for the server can be chosen at will, let's +take "oping_server". In the second terminal window, execute: + +``` +$ irm bind proc 2337 name oping_server +$ irm register name oping_server layer local_layer +``` + +The IRMd and IPCPd in terminal one will now acknowledge that the name is +bound and registered: + +``` +==02301== irmd(II): Bound process 2337 to name oping_server. +==02324== ipcpd-local(II): Registered 4721372d. +==02301== irmd(II): Registered oping_server in local_layer as +4721372d. +``` + +Ouroboros registers name not in plaintext but using a (configurable) +hashing algorithm. The default hash is a 256 bit SHA3 hash. The output +in the logs is truncated to the first 4 bytes in a HEX notation. + +Now that we have bound and registered our server, we can connect from +the client. In the second terminal window, start an oping client with +destination oping_server and it will begin pinging: + +``` +$ oping -n oping_server -c 5 +Pinging oping_server with 64 bytes of data: + +64 bytes from oping_server: seq=0 time=0.694 ms +64 bytes from oping_server: seq=1 time=0.364 ms +64 bytes from oping_server: seq=2 time=0.190 ms +64 bytes from oping_server: seq=3 time=0.269 ms +64 bytes from oping_server: seq=4 time=0.351 ms + +--- oping_server ping statistics --- +5 SDUs transmitted, 5 received, 0% packet loss, time: 5001.744 ms +rtt min/avg/max/mdev = 0.190/0.374/0.694/0.192 ms +``` + +The server will acknowledge that it has a new flow connected on flow +descriptor 64, which will time out a few seconds after the oping client +stops sending: + +``` +New flow 64. +Flow 64 timed out. +``` + +The IRMd and IPCP logs provide some additional output detailing the flow +allocation process: + +``` +==02324== ipcpd-local(DB): Allocating flow to 4721372d on fd 64. +==02301== irmd(DB): Flow req arrived from IPCP 2324 for 4721372d. +==02301== irmd(II): Flow request arrived for oping_server. +==02324== ipcpd-local(II): Pending local allocation request on fd 64. +==02301== irmd(II): Flow on port_id 0 allocated. +==02324== ipcpd-local(II): Flow allocation completed, fds (64, 65). +==02301== irmd(II): Flow on port_id 1 allocated. +==02301== irmd(DB): New instance (2337) of oping added. +==02301== irmd(DB): This process accepts flows for: +==02301== irmd(DB): oping_server +``` + +First, the IPCPd shows that it will allocate a flow towards a +destination hash "4721372d" (truncated). The IRMd logs that IPCPd 2324 +(our local IPCPd) requests a flow towards any process that is listening +for "4721372d", and resolves it to "oping_server", as that is a +process that is bound to that name. At this point, the local IPCPd has a +pending flow on the client side. Since this is the first port_id in the +system, it has port_id 0. The server will accept the flow and the other +end of the flow gets port_id 1. The local IPCPd sees that the flow +allocation is completed. Internally it sees the endpoints as flow +descriptors 64 and 65 which map to port_id 0 and port_id 1. The IPCP +cannot directly access port_ids, they are assigned and managed by the +IRMd. After it has accepted the flow, the oping server enters +flow_accept() again. The IRMd notices the instance and reports that it +accepts flows for "oping_server". + +This concludes this first short tutorial. All running processes can be +terminated by issuing a Ctrl-C command in their respective terminals or +you can continue with the next tutorial. diff --git a/content/docs/tutorials/tutorial-2.md b/content/docs/tutorials/tutorial-2.md new file mode 100644 index 0000000..392a659 --- /dev/null +++ b/content/docs/tutorials/tutorial-2.md @@ -0,0 +1,297 @@ +--- +title: "Tutorial 2: Adding a layer" +draft: false +--- + +In this tutorial we will add a *normal layer* on top of the local layer. +Make sure you have a local layer running. The network will look like +this: + + + +Let's start adding the normal layer. We will first bootstrap a normal +IPCP, with name "normal_1" into the "normal_layer" (using default +options). In terminal 2, type: + +``` +$ irm ipcp bootstrap type normal name normal_1 layer normal_layer +``` + +The IRMd and IPCP will report the bootstrap: + +``` +==02301== irmd(II): Created IPCP 4363. +==04363== normal-ipcp(DB): IPCP got address 465922905. +==04363== directory(DB): Bootstrapping directory. +==04363== directory(II): Directory bootstrapped. +==04363== normal-ipcp(DB): Bootstrapped in layer normal_layer. +==02301== irmd(II): Bootstrapped IPCP 4363 in layer normal_layer. +==02301== irmd(DB): New instance (4363) of ipcpd-normal added. +==02301== irmd(DB): This process accepts flows for: +``` + +The new IPCP has pid 4363. It also generated an *address* for itself, +465922905. Then it bootstrapped a directory. The directory will map +registered names to an address or a set of addresses. In the normal DHT +the current default (and only option) for the directory is a Distributed +Hash Table (DHT) based on the Kademlia protocol, similar to the DHT used +in the mainline BitTorrent as specified by the +[BEP5](http://www.bittorrent.org/beps/bep_0005.html). This DHT will use +the hash algorithm specified for the layer (default is 256-bit SHA3) +instead of the SHA1 algorithm used by Kademlia. Just like any +Ouroboros-capable process, the IRMd will notice a new instance of the +normal IPCP. We will now bind this IPCP to some names and register them +in the local_layer: + +``` +$ irm bind ipcp normal_1 name normal_1 +$ irm bind ipcp normal_1 name normal_layer +$ irm register name normal_1 layer local_layer +$ irm register name normal_layer layer local_layer +``` + +The "irm bind ipcp" call is a shorthand for the "irm bind proc" call +that uses the ipcp name instead of the pid for convenience. Note that +we have bound the same process to two different names. This is to +allow enrollment using a layer name (anycast) instead of a specific +ipcp_name. The IRMd and local IPCP should log the following, just as +in tutorial 1: + +``` +==02301== irmd(II): Bound process 4363 to name normal_1. +==02301== irmd(II): Bound process 4363 to name normal_layer. +==02324== ipcpd-local(II): Registered e9504761. +==02301== irmd(II): Registered normal_1 in local_layer as e9504761. +==02324== ipcpd-local(II): Registered f40ee0f0. +==02301== irmd(II): Registered normal_layer in local_layer as +f40ee0f0. +``` + +We will now create a second IPCP and enroll it in the normal_layer. +Like the "irm ipcp bootstrap command", the "irm ipcp enroll" command +will create the IPCP if an IPCP with that name does not yet exist in the +system. An "autobind" option is a shorthand for binding the IPCP to +the IPCP name and the layer name. + +``` +$ irm ipcp enroll name normal_2 layer normal_layer autobind +``` + +The activity is shown by the output of the IRMd and the IPCPs. Let's +break it down. First, the new normal IPCP is created and bound to its +process name: + +``` +==02301== irmd(II): Created IPCP 13569. +==02301== irmd(II): Bound process 13569 to name normal_2. +``` + +Next, that IPCP will *enroll* with an existing member of the layer +"normal_layer". To do that it first allocates a flow over the local +layer: + +``` +==02324== ipcpd-local(DB): Allocating flow to f40ee0f0 on fd 64. +==02301== irmd(DB): Flow req arrived from IPCP 2324 for f40ee0f0. +==02301== irmd(II): Flow request arrived for normal_layer. +==02324== ipcpd-local(II): Pending local allocation request on fd 64. +==02301== irmd(II): Flow on port_id 0 allocated. +==02324== ipcpd-local(II): Flow allocation completed, fds (64, 65). +==02301== irmd(II): Flow on port_id 1 allocated. +``` + +Over this flow, it connects to the enrollment component of the normal_1 +IPCP. It sends some information that it will speak the Ouroboros +Enrollment Protocol (OEP). Then it will receive boot information from +normal_1 (the configuration of the layer that was provided when we +bootstrapped the normal_1 process), such as the hash it will use for +the directory. It signals normal_1 that it got the information so that +normal_1 knows this was successful. It will also get an address. After +enrollment is complete, both normal_1 and normal_2 will be ready to +accept incoming flows: + +``` +==13569== connection-manager(DB): Sending cacep info for protocol OEP to +fd 64. +==13569== enrollment(DB): Getting boot information. +==02301== irmd(DB): New instance (4363) of ipcpd-normal added. +==02301== irmd(DB): This process accepts flows for: +==02301== irmd(DB): normal_layer +==02301== irmd(DB): normal_1 +==04363== enrollment(DB): Enrolling a new neighbor. +==04363== enrollment(DB): Sending enrollment info (49 bytes). +==13569== enrollment(DB): Received enrollment info (49 bytes). +==13569== normal-ipcp(DB): IPCP got address 416743497. +==04363== enrollment(DB): Neighbor enrollment successful. +==02301== irmd(DB): New instance (13569) of ipcpd-normal added. +==02301== irmd(DB): This process accepts flows for: +==02301== irmd(DB): normal_2 +``` + +Now that the member is enrolled, normal_1 and normal_2 will deallocate +the flow over which it enrolled and signal the IRMd that the enrollment +was successful: + +``` +==02301== irmd(DB): Partial deallocation of port_id 0 by process +13569. +==02301== irmd(DB): Partial deallocation of port_id 1 by process 4363. +==02301== irmd(II): Completed deallocation of port_id 0 by process +2324. +==02301== irmd(II): Completed deallocation of port_id 1 by process +2324. +==02324== ipcpd-local(II): Flow with fd 64 deallocated. +==02324== ipcpd-local(II): Flow with fd 65 deallocated. +==13569== normal-ipcp(II): Enrolled with normal_layer. +==02301== irmd(II): Enrolled IPCP 13569 in layer normal_layer. +``` + +Now that normal_2 is a full member of the layer, the irm tool will +complete the autobind option and bind normal_2 to the name +"normal_layer" so it can also enroll new members. + +``` +==02301== irmd(II): Bound process 13569 to name normal_layer. +``` + +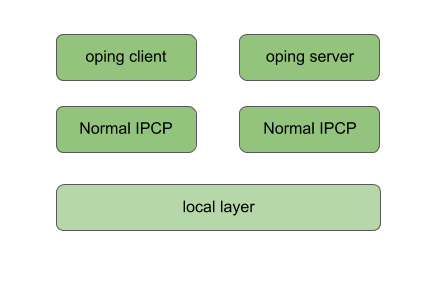 + +At this point, have two enrolled members of the normal_layer. What we +need to do next is connect them. We will need a *management flow*, for +the management network, which is used to distribute point-to-point +information (such as routing information) and a *data transfer flow* +over which the layer will forward traffic coming either from higher +layers or internal components (such as the DHT and flow allocator). They +can be established in any order, but it is recommended to create the +management network first to achieve the minimal setup times for the +network layer: + +``` +$ irm ipcp connect name normal_2 dst normal_1 comp mgmt +$ irm ipcp connect name normal_2 dst normal_1 comp dt +``` + +The IPCP and IRMd log the flow and connection establishment: + +``` +==02301== irmd(DB): Connecting Management to normal_1. +==02324== ipcpd-local(DB): Allocating flow to e9504761 on fd 64. +==02301== irmd(DB): Flow req arrived from IPCP 2324 for e9504761. +==02301== irmd(II): Flow request arrived for normal_1. +==02324== ipcpd-local(II): Pending local allocation request on fd 64. +==02301== irmd(II): Flow on port_id 0 allocated. +==02324== ipcpd-local(II): Flow allocation completed, fds (64, 65). +==02301== irmd(II): Flow on port_id 1 allocated. +==13569== connection-manager(DB): Sending cacep info for protocol LSP to +fd 64. +==04363== link-state-routing(DB): Type mgmt neighbor 416743497 added. +==02301== irmd(DB): New instance (4363) of ipcpd-normal added. +==02301== irmd(DB): This process accepts flows for: +==02301== irmd(DB): normal_layer +==02301== irmd(DB): normal_1 +==13569== link-state-routing(DB): Type mgmt neighbor 465922905 added. +==02301== irmd(II): Established Management connection between IPCP 13569 +and normal_1. +``` + +The IPCPs established a management flow between the link-state routing +components (currently that is the only component that needs a management +flow). The output is similar for the data transfer flow, however, +creating a data transfer flow triggers some additional activity: + +``` +==02301== irmd(DB): Connecting Data Transfer to normal_1. +==02324== ipcpd-local(DB): Allocating flow to e9504761 on fd 66. +==02301== irmd(DB): Flow req arrived from IPCP 2324 for e9504761. +==02301== irmd(II): Flow request arrived for normal_1. +==02324== ipcpd-local(II): Pending local allocation request on fd 66. +==02301== irmd(II): Flow on port_id 2 allocated. +==02324== ipcpd-local(II): Flow allocation completed, fds (66, 67). +==02301== irmd(II): Flow on port_id 3 allocated. +==13569== connection-manager(DB): Sending cacep info for protocol dtp to +fd 65. +==04363== dt(DB): Added fd 65 to SDU scheduler. +==04363== link-state-routing(DB): Type dt neighbor 416743497 added. +==02301== irmd(DB): New instance (4363) of ipcpd-normal added. +==02301== irmd(DB): This process accepts flows for: +==02301== irmd(DB): normal_layer +==02301== irmd(DB): normal_1 +==13569== dt(DB): Added fd 65 to SDU scheduler. +==13569== link-state-routing(DB): Type dt neighbor 465922905 added. +==13569== dt(DB): Could not get nhop for addr 465922905. +==02301== irmd(II): Established Data Transfer connection between IPCP +13569 and normal_1. +==13569== dt(DB): Could not get nhop for addr 465922905. +==13569== dht(DB): Enrollment of DHT completed. +``` + +First, the data transfer flow is added to the SDU scheduler. Next, the +neighbor's address is added to the link-state database and a Link-State +Update message is broadcast over the management network. Finally, if the +DHT is not yet enrolled, it will try to do so when it detects a new data +transfer flow. Since this is the first data transfer flow in the +network, the DHT will try to enroll. It may take some time for the +routing entry to get inserted to the forwarding table, so the DHT +re-tries a couple of times (this is the "could not get nhop" message +in the debug log). + +Our oping server is not registered yet in the normal layer. Let's +register it in the normal layer as well, and connect the client: + +``` +$ irm r n oping_server layer normal_layer +$ oping -n oping_server -c 5 +``` + +The IRMd and IPCP will log: + +``` +==02301== irmd(II): Registered oping_server in normal_layer as +465bac77. +==02301== irmd(II): Registered oping_server in normal_layer as +465bac77. +==02324== ipcpd-local(DB): Allocating flow to 4721372d on fd 68. +==02301== irmd(DB): Flow req arrived from IPCP 2324 for 4721372d. +==02301== irmd(II): Flow request arrived for oping_server. +==02324== ipcpd-local(II): Pending local allocation request on fd 68. +==02301== irmd(II): Flow on port_id 4 allocated. +==02324== ipcpd-local(II): Flow allocation completed, fds (68, 69). +==02301== irmd(II): Flow on port_id 5 allocated. +==02301== irmd(DB): New instance (2337) of oping added. +==02301== irmd(DB): This process accepts flows for: +==02301== irmd(DB): oping_server +==02301== irmd(DB): Partial deallocation of port_id 4 by process 749. +==02301== irmd(II): Completed deallocation of port_id 4 by process +2324. +==02324== ipcpd-local(II): Flow with fd 68 deallocated. +==02301== irmd(DB): Dead process removed: 749. +==02301== irmd(DB): Partial deallocation of port_id 5 by process 2337. +==02301== irmd(II): Completed deallocation of port_id 5 by process +2324. +==02324== ipcpd-local(II): Flow with fd 69 deallocated. +``` + +The client connected over the local layer instead of the normal layer. +This is because the IRMd prefers the local layer. If we unregister the +name from the local layer, the client will connect over the normal +layer: + +``` +$ irm unregister name oping_server layer local_layer +$ oping -n oping_server -c 5 +``` + +As shown by the logs (the normal IPCP doesn't log the flow allocation): + +``` +==02301== irmd(DB): Flow req arrived from IPCP 13569 for 465bac77. +==02301== irmd(II): Flow request arrived for oping_server. +==02301== irmd(II): Flow on port_id 5 allocated. +==02301== irmd(II): Flow on port_id 4 allocated. +==02301== irmd(DB): New instance (2337) of oping added. +==02301== irmd(DB): This process accepts flows for: +==02301== irmd(DB): oping_server +``` + +This concludes tutorial 2. You can shut down everything or continue with +tutorial 3. diff --git a/content/docs/tutorials/tutorial-3.md b/content/docs/tutorials/tutorial-3.md new file mode 100644 index 0000000..2dd0645 --- /dev/null +++ b/content/docs/tutorials/tutorial-3.md @@ -0,0 +1,210 @@ +--- +title: "Tutorial 3: IPCP statistics" +draft: false +--- + +For this tutorial, you should have a local layer, a normal layer and a +ping server registered in the normal layer. You will need to have the +FUSE libraries installed and Ouroboros compiled with FUSE support. We +will show you how to get some statistics from the network layer which is +exported by the IPCPs at /tmp/ouroboros (this mountpoint can be set at +compile time): + +``` +$ tree /tmp/ouroboros +/tmp/ouroboros/ +|-- ipcpd-normal.13569 +| |-- dt +| | |-- 0 +| | |-- 1 +| | `-- 65 +| `-- lsdb +| |-- 416743497.465922905 +| |-- 465922905.416743497 +| |-- dt.465922905 +| `-- mgmt.465922905 +`-- ipcpd-normal.4363 + |-- dt + | |-- 0 + | |-- 1 + | `-- 65 + `-- lsdb + |-- 416743497.465922905 + |-- 465922905.416743497 + |-- dt.416743497 + `-- mgmt.416743497 + +6 directories, 14 files +``` + +There are two filesystems, one for each normal IPCP. Currently, it shows +information for two components: data transfer and the link-state +database. The data transfer component lists flows on known flow +descriptors. The flow allocator component will usually be on fd 0 and +the directory (DHT). There is a single (N-1) data transfer flow on fd 65 +that the IPCPs can use to send data (these fd's will usually not be the +same). The routing component sees that data transfer flow as two +unidirectional links. It has a management flow and data transfer flow to +its neighbor. Let's have a look at the data transfer flow in the +network: + +``` +$ cat /tmp/ouroboros/ipcpd-normal.13569/dt/65 +Flow established at: 2018-03-07 18:47:43 +Endpoint address: 465922905 +Queued packets (rx): 0 +Queued packets (tx): 0 + +Qos cube 0: + sent (packets): 4 + sent (bytes): 268 + rcvd (packets): 3 + rcvd (bytes): 298 + local sent (packets): 4 + local sent (bytes): 268 + local rcvd (packets): 3 + local rcvd (bytes): 298 + dropped ttl (packets): 0 + dropped ttl (bytes): 0 + failed writes (packets): 0 + failed writes (bytes): 0 + failed nhop (packets): 0 + failed nhop (bytes): 0 + +<no traffic on other qos cubes> +``` + +The above output shows the statistics for the data transfer component of +the IPCP that enrolled into the layer. It shows the time the flow was +established, the endpoint address and the number of packets that are in +the incoming and outgoing queues. Then it lists packet statistics per +QoS cube. It sent 4 packets, and received 3 packets. All the packets +came from local sources (internal components of the IPCP) and were +delivered to local destinations. Let's have a look where they went. + +``` +$ cat /tmp/ouroboros/ipcpd-normal.13569/dt/1 +Flow established at: 2018-03-07 18:47:43 +Endpoint address: flow-allocator +Queued packets (rx): 0 +Queued packets (tx): 0 + +<no packets on this flow> +``` + +There is no traffic on fd 0, which is the flow allocator component. This +will only be used when higher layer applications will use this normal +layer. Let's have a look at fd 1. + +``` +$ cat /tmp/ouroboros/ipcpd-normal.13569/dt/1 +Flow established at: 2018-03-07 18:47:43 +Endpoint address: dht +Queued packets (rx): 0 +Queued packets (tx): 0 + +Qos cube 0: + sent (packets): 3 + sent (bytes): 298 + rcvd (packets): 0 + rcvd (bytes): 0 + local sent (packets): 0 + local sent (bytes): 0 + local rcvd (packets): 6 + local rcvd (bytes): 312 + dropped ttl (packets): 0 + dropped ttl (bytes): 0 + failed writes (packets): 0 + failed writes (bytes): 0 + failed nhop (packets): 2 + failed nhop (bytes): 44 + +<no traffic on other qos cubes> +``` + +The traffic for the directory (DHT) is on fd1. Take note that this is +from the perspective of the data transfer component. The data transfer +component sent 3 packets to the DHT, these are the 3 packets it received +from the data transfer flow. The data transfer component received 6 +packets from the DHT. It only sent 4 on fd 65. 2 packets failed because +of nhop. This is because the forwarding table was being updated from the +routing table. Let's send some traffic to the oping server. + +``` +$ oping -n oping_server -i 0 +Pinging oping_server with 64 bytes of data: + +64 bytes from oping_server: seq=0 time=0.547 ms +... +64 bytes from oping_server: seq=999 time=0.184 ms + +--- oping_server ping statistics --- +1000 SDUs transmitted, 1000 received, 0% packet loss, time: 106.538 ms +rtt min/avg/max/mdev = 0.151/0.299/2.269/0.230 ms +``` + +This sent 1000 packets to the server. Let's have a look at the flow +allocator: + +``` +$ cat /tmp/ouroboros/ipcpd-normal.13569/dt/0 +Flow established at: 2018-03-07 18:47:43 +Endpoint address: flow-allocator +Queued packets (rx): 0 +Queued packets (tx): 0 + +Qos cube 0: + sent (packets): 1 + sent (bytes): 59 + rcvd (packets): 0 + rcvd (bytes): 0 + local sent (packets): 0 + local sent (bytes): 0 + local rcvd (packets): 1 + local rcvd (bytes): 51 + dropped ttl (packets): 0 + dropped ttl (bytes): 0 + failed writes (packets): 0 + failed writes (bytes): 0 + failed nhop (packets): 0 + failed nhop (bytes): 0 + +<no traffic on other qos cubes> +``` + +The flow allocator has sent and received a message: a request and a +response for the flow allocation between the oping client and server. +The data transfer flow will also have additional traffic: + +``` +$ cat /tmp/ouroboros/ipcpd-normal.13569/dt/65 +Flow established at: 2018-03-07 18:47:43 +Endpoint address: 465922905 +Queued packets (rx): 0 +Queued packets (tx): 0 + +Qos cube 0: + sent (packets): 1013 + sent (bytes): 85171 + rcvd (packets): 1014 + rcvd (bytes): 85373 + local sent (packets): 13 + local sent (bytes): 1171 + local rcvd (packets): 14 + local rcvd (bytes): 1373 + dropped ttl (packets): 0 + dropped ttl (bytes): 0 + failed writes (packets): 0 + failed writes (bytes): 0 + failed nhop (packets): 0 + failed nhop (bytes): 0 +``` + +This shows the traffic from the oping application. The additional +traffic (the oping sent 1000, the flow allocator 1 and the DHT +previously sent 3) is additional DHT traffic (the DHT periodically +updates). Also note that the traffic reported on the link includes the +FRCT and data transfer headers which in the default configuration is 20 +bytes per packet. + +This concludes tutorial 3. diff --git a/content/docs/tutorials/tutorial-4.md b/content/docs/tutorials/tutorial-4.md new file mode 100644 index 0000000..fd7db3a --- /dev/null +++ b/content/docs/tutorials/tutorial-4.md @@ -0,0 +1,123 @@ +--- +title: "Tutorial 4: Connecting two machines over Ethernet" +draft: false +--- + +In this tutorial we will connect two machines over an Ethernet network +using the eth-llc or eth-dix IPCPs. The eth-llc use of the IEEE 802.2 +Link Layer Control (LLC) service type 1 frame header. The eth-dix IPCP +uses DIX (DEC, Intel, Xerox) Ethernet, also known as Ethernet II. Both +provide a connectionless packet service with unacknowledged delivery. + +Make sure that you have an Ouroboros IRM daemon running on both +machines: + +``` +$ sudo irmd --stdout +``` + +The eth-llc and eth-dix IPCPs attach to an ethernet interface, which is +specified by its device name. The device name can be found in a number +of ways, we'll use the "ip" command here: + +``` +$ ip a +1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN +group default qlen 1 +link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 +... +2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast +state UP group default qlen 1000 +link/ether fa:16:3e:42:00:38 brd ff:ff:ff:ff:ff:ff +... +3: ens6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast +state UP group default qlen 1000 +link/ether fa:16:3e:00:76:c2 brd ff:ff:ff:ff:ff:ff +... +``` + +The output of this command differs between operating systems and +distributions. The interface we need to use in our setup is "ens3" on +both machines, but for you it may be something like "eth0" or +"enp0s7f1" if you are on a wired LAN, or something like "wlan0" or +"wlp2s0" if you are on a Wi-Fi network. For Wi-Fi networks, we +recommend using the eth-dix. + +Usually the interface you will use is the one that has an IP address for +your LAN set. Note that you do not need to have an IP address for this +tutorial, but do make sure the interface is UP. + +Now that we know the interfaces to connect to the network with, let's +start the eth-llc/eth-dix IPCPs. The eth-llc/eth-dix layers don't have +an enrollment phase, all eth-llc IPCPs that are connected to the same +Ethernet, will be part of the layer. For eth-dix IPCPs the layers can be +separated by ethertype. The eth-llc and eth-dix IPCPs can only be +bootstrapped, so care must be taken by to provide the same hash +algorithm to all eth-llc and eth-dix IPCPs that should be in the same +network. We use the default (256-bit SHA3) for the hash and 0xa000 for +the Ethertype for the DIX IPCP. For our setup, it's the exact same +command on both machines. You will likely need to set a different +interface name on each machine. The irm tool allows abbreviated commands +(it is modelled after the "ip" command), which we show here (both +commands do the same): + +``` +node0: $ irm ipcp bootstrap type eth-llc name llc layer eth dev ens3 +node1: $ irm i b t eth-llc n llc l eth if ens3 +``` + +Both IRM daemons should acknowledge the creation of the IPCP: + +``` +==26504== irmd(II): Ouroboros IPC Resource Manager daemon started... +==26504== irmd(II): Created IPCP 27317. +==27317== ipcpd/eth-llc(II): Using raw socket device. +==27317== ipcpd/eth-llc(DB): Bootstrapped IPCP over Ethernet with LLC +with pid 27317. +==26504== irmd(II): Bootstrapped IPCP 27317 in layer eth. +``` + +If it failed, you may have mistyped the interface name, or your system +may not have a valid raw packet API. We are using GNU/Linux machines, so +the IPCP announces that it is using a [raw +socket](http://man7.org/linux/man-pages/man2/socket.2.html) device. On +OS X, the default is a [Berkeley Packet Filter +(BPF)](http://www.manpages.info/macosx/bpf.4.html) device, and on +FreeBSD, the default is a +[netmap](http://info.iet.unipi.it/~luigi/netmap/) device. See the +[compilation options](/compopt) for more information on choosing the +raw packet API. + +The Ethernet layer is ready to use. We will now create a normal layer +on top of it, just like we did over the local layer in the second +tutorial. We are showing some different ways of entering these +commands on the two machines: + +``` +node0: +$ irm ipcp bootstrap type normal name normal_0 layer normal_layer +$ irm bind ipcp normal_0 name normal_0 +$ irm b i normal_0 n normal_layer +$ irm register name normal_layer layer eth +$ irm r n normal_0 l eth +node1: +$ irm ipcp enroll name normal_1 layer normal_layer autobind +$ irm r n normal_layer l eth +$ irm r n normal_1 l eth +``` + +The IPCPs should acknowledge the enrollment in their logs: + +``` +node0: +==27452== enrollment(DB): Enrolling a new neighbor. +==27452== enrollment(DB): Sending enrollment info (47 bytes). +==27452== enrollment(DB): Neighbor enrollment successful. +node1: +==27720== enrollment(DB): Getting boot information. +==27720== enrollment(DB): Received enrollment info (47 bytes). +``` + +You can now continue to set up a management flow and data transfer +flow for the normal layer, like in tutorial 2. This concludes the +fourth tutorial. |